Class 8
Importing, Renaming, Anonymizing
Preparation Materials
Agenda
Today we’ll focus on:
- Start working on Homework 1 (survey analysis)
- importing data from Google Sheets
- previewing the data format
- column operations
Importing Data
Importing from Google Sheets
Let’s load up our data from the sheet (without the emails):
https://r4ds.hadley.nz/spreadsheets.html#google-sheets
If you want to access a public sheet, you can avoid the authentication process by using gs4_deauth():
To access sheets that are protected, you can alternatively use gs4_auth("your@email.here"), which will specify the account you want to use. When you try to access the sheet, a login process will be initiated.
You will need to authorize access by checking the circled box. If you already authorized without checking that, restart your R session and try again.
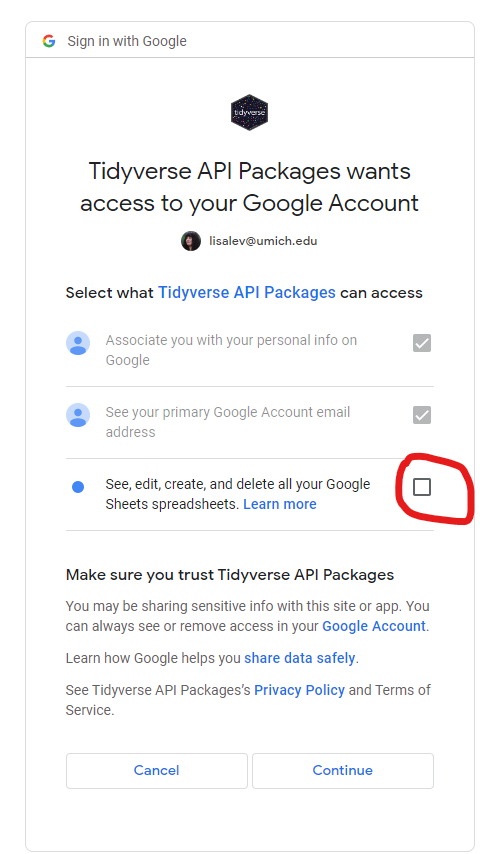
Use the advice from the data import reading for help with renaming columns and changing data types.
It’s hard to “preview” these data:
#> # A tibble: 6 × 12
#> Timestamp Did you grow up speaking English …¹ If you did grow up s…²
#> <dttm> <chr> <list>
#> 1 2024-09-17 11:39:06 Yes <dbl [1]>
#> 2 2024-09-17 11:41:27 Yes <dbl [1]>
#> 3 2024-09-17 11:42:33 No <chr [1]>
#> 4 2024-09-17 11:42:43 No <chr [1]>
#> 5 2024-09-17 11:44:16 Yes <dbl [1]>
#> 6 2024-09-17 11:52:00 Yes <dbl [1]>
#> # ℹ abbreviated names:
#> # ¹`Did you grow up speaking English in the United States?`,
#> # ²`If you did grow up speaking English in the United States, what zip code would most accurately represent where you feel your language variety is "from"? If you did not, write "NA".`
#> # ℹ 9 more variables:
#> # `Q94: “He used to nap on the couch, but he sprawls out in that new lounge chair anymore.”` <dbl>,
#> # `Q95: “I do exclusively figurative paintings anymore.”` <dbl>,
#> # `Q96: “Pantyhose are so expensive anymore that I just try to get a good suntan and forget about it.”` <dbl>, …You can open it in the original sheet or in the data viewer to get a better look!
Renaming Columns/Variables
I want to demonstrate some things with some other data, so again I’m going to make some up!
df_sample <- tibble(
# generate 50 different names
`full name` = ch_name(50),
# generate 10 different jobs and repeat 5 times
job = rep(ch_job(10),5),
# sentence ratings randomly sampled on a 0-10 scale with preset means
`1` = sample(0:10, prob = dnorm(0:10, mean = 8.5, sd = 1), size = 50, replace = TRUE),
`2` = sample(0:10, prob = dnorm(0:10, mean = 8.5, sd = 1), size = 50, replace = TRUE),
`3` = sample(0:10, prob = dnorm(0:10, mean = 5, sd = 1), size = 50, replace = TRUE),
`4` = sample(0:10, prob = dnorm(0:10, mean = 4, sd = 1), size = 50, replace = TRUE)
)What’s wrong with those column names?
Let’s fix them up. Sometimes you want specific column names. You can use the rename() function from dplyr:
df_sample |>
# new name on left, old name on right, comma separate lines
rename(name = `full name`,
lovelysentence = `1`,
nicesentence = `2`,
notsogoodsentence = `3`,
badsentence = `4`
)#> # A tibble: 50 × 6
#> name job lovelysentence nicesentence notsogoodsentence badsentence
#> <chr> <chr> <int> <int> <int> <int>
#> 1 Kim Metz Tran… 9 10 6 4
#> 2 Dr. Chad Kli… Medi… 8 6 3 5
#> 3 Chancy Schow… Nava… 8 7 6 3
#> 4 Pierce Klein Edit… 8 9 4 5
#> 5 Jazmyn Abern… Arbo… 9 9 5 1
#> 6 Kieth Christ… Desi… 9 9 3 4
#> 7 Kyan Goldner Educ… 8 9 5 3
#> 8 Frazier Seng… Food… 7 10 4 3
#> 9 Abbott Smith… Educ… 8 8 6 4
#> 10 Pearl Schmidt Teac… 10 8 4 2
#> # ℹ 40 more rowsOne automated method is to use janitor::clean_names() - if you want to save the output make sure to assign to the same or another dataframe:
When you import, you can also change how you want the column names to be read, or whether they are present at all. It depends on the function and type of data, but here are some examples of changing the Google Sheet import:
# put your sheet URL in an object so it's easier to repeat
surveysheet <- "https://docs.google.com/spreadsheets/d/1NR69Bt_SJJIrTOrWjmomGk5flXGroA_4Umd3Hntl_ZA/"
df_survey <- read_sheet(surveysheet, col_names = FALSE, skip = 1) |>
select(-`...2`) |>
glimpse()#> Rows: 16
#> Columns: 12
#> $ ...1 <dttm> 2024-09-17 11:39:06, 2024-09-17 11:41:27, 2024-09-17 11:42:33, …
#> $ ...3 <chr> "Yes", "Yes", "No", "No", "Yes", "Yes", "Yes", "Yes", "Yes", "No…
#> $ ...4 <list> 49504, 48867, "NA", "NA", 11355, 34695, 10580, 48180, 10013, "N…
#> $ ...5 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 1
#> $ ...6 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 3, 1, 1, 1
#> $ ...7 <dbl> 1, 2, 2, 4, 3, 4, 2, 2, 1, 2, 1, 4, 2, 2, 5, 2
#> $ ...8 <dbl> 1, 5, 2, 4, 2, 3, 2, 1, 2, 2, 2, 4, 3, 1, 1, 2
#> $ ...9 <chr> "median (or median strip)", "median (or median strip)", "I have …
#> $ ...10 <chr> "I have no word for this", "I have no word for this", "I have no…
#> $ ...11 <chr> "soda", "soda", "soft drink", "fizzy drink", "soda", "soda", "so…
#> $ ...12 <chr> "[æ] as in “sat”", "[æ] as in “sat”", "[æ] as in “sat”", "[æ] as…
#> $ ...13 <chr> "[æ] as in “snap” (“app-ricot”)", "[æ] as in “snap” (“app-ricot”…df_survey <- read_sheet(surveysheet, col_names = c("timestamp","email", "usenglish", "zip", "q94", "q95", "q96", "q97", "q264", "q142", "q30", "q151", "q178"), skip = 1) |>
select(-email) |>
glimpse()#> Rows: 16
#> Columns: 12
#> $ timestamp <dttm> 2024-09-17 11:39:06, 2024-09-17 11:41:27, 2024-09-17 11:42:…
#> $ usenglish <chr> "Yes", "Yes", "No", "No", "Yes", "Yes", "Yes", "Yes", "Yes",…
#> $ zip <list> 49504, 48867, "NA", "NA", 11355, 34695, 10580, 48180, 10013…
#> $ q94 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 1
#> $ q95 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 3, 1, 1, 1
#> $ q96 <dbl> 1, 2, 2, 4, 3, 4, 2, 2, 1, 2, 1, 4, 2, 2, 5, 2
#> $ q97 <dbl> 1, 5, 2, 4, 2, 3, 2, 1, 2, 2, 2, 4, 3, 1, 1, 2
#> $ q264 <chr> "median (or median strip)", "median (or median strip)", "I h…
#> $ q142 <chr> "I have no word for this", "I have no word for this", "I hav…
#> $ q30 <chr> "soda", "soda", "soft drink", "fizzy drink", "soda", "soda",…
#> $ q151 <chr> "[æ] as in “sat”", "[æ] as in “sat”", "[æ] as in “sat”", "[æ…
#> $ q178 <chr> "[æ] as in “snap” (“app-ricot”)", "[æ] as in “snap” (“app-ri…# make a vector of column names first
my_columns <- c("timestamp","email", "usenglish", "zip", "q94", "q95", "q96", "q97", "q264", "q142", "q30", "q151", "q178")
df_survey <- read_sheet(surveysheet, col_names = my_columns, skip = 1) |>
select(-email) |>
glimpse()#> Rows: 16
#> Columns: 12
#> $ timestamp <dttm> 2024-09-17 11:39:06, 2024-09-17 11:41:27, 2024-09-17 11:42:…
#> $ usenglish <chr> "Yes", "Yes", "No", "No", "Yes", "Yes", "Yes", "Yes", "Yes",…
#> $ zip <list> 49504, 48867, "NA", "NA", 11355, 34695, 10580, 48180, 10013…
#> $ q94 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 1
#> $ q95 <dbl> 1, 2, 2, 4, 2, 1, 1, 2, 1, 2, 2, 2, 3, 1, 1, 1
#> $ q96 <dbl> 1, 2, 2, 4, 3, 4, 2, 2, 1, 2, 1, 4, 2, 2, 5, 2
#> $ q97 <dbl> 1, 5, 2, 4, 2, 3, 2, 1, 2, 2, 2, 4, 3, 1, 1, 2
#> $ q264 <chr> "median (or median strip)", "median (or median strip)", "I h…
#> $ q142 <chr> "I have no word for this", "I have no word for this", "I hav…
#> $ q30 <chr> "soda", "soda", "soft drink", "fizzy drink", "soda", "soda",…
#> $ q151 <chr> "[æ] as in “sat”", "[æ] as in “sat”", "[æ] as in “sat”", "[æ…
#> $ q178 <chr> "[æ] as in “snap” (“app-ricot”)", "[æ] as in “snap” (“app-ri…Why isn’t my_columns in quotes?
Adding IDs
There are a bunch of ways to make a new, anonymous ID number for data. It’s very simple if data are wide and you want one ID per row:
# this strategy works if you know you have one participant per row
df_sample |>
# .before allows you to specify where to place the column
mutate(ID = 1:50, .before = full_name) |>
select(-full_name)#> # A tibble: 50 × 6
#> ID job x1 x2 x3 x4
#> <int> <chr> <int> <int> <int> <int>
#> 1 1 Transport planner 9 10 6 4
#> 2 2 Medical secretary 8 6 3 5
#> 3 3 Naval architect 8 7 6 3
#> 4 4 Editorial assistant 8 9 4 5
#> 5 5 Arboriculturist 9 9 5 1
#> 6 6 Designer, multimedia 9 9 3 4
#> 7 7 Education administrator 8 9 5 3
#> 8 8 Food technologist 7 10 4 3
#> 9 9 Education officer, museum 8 8 6 4
#> 10 10 Teacher, English as a foreign language 10 8 4 2
#> # ℹ 40 more rowsThis method isn’t great though because it’s not flexible for different numbers of participants. Ideally you can use the data to determine how many numbers you need:
# using nrow()
df_sample |>
mutate(ID = 1:nrow(df_sample), .before = full_name) |>
select(-full_name)#> # A tibble: 50 × 6
#> ID job x1 x2 x3 x4
#> <int> <chr> <int> <int> <int> <int>
#> 1 1 Transport planner 9 10 6 4
#> 2 2 Medical secretary 8 6 3 5
#> 3 3 Naval architect 8 7 6 3
#> 4 4 Editorial assistant 8 9 4 5
#> 5 5 Arboriculturist 9 9 5 1
#> 6 6 Designer, multimedia 9 9 3 4
#> 7 7 Education administrator 8 9 5 3
#> 8 8 Food technologist 7 10 4 3
#> 9 9 Education officer, museum 8 8 6 4
#> 10 10 Teacher, English as a foreign language 10 8 4 2
#> # ℹ 40 more rowsIf you have long data with repeated observations, you have to use groups. This is one convenient method:
# a fancier way that will group by another variable is to use
# cur_group_id() and group on an identifying variable
# this will work with multiple rows per group
df_sample_anon <- df_sample |>
group_by(full_name) |>
mutate(ID = cur_group_id(), .before = full_name) |>
# ungroup so we can truly remove the name
ungroup() |>
# remove the name variable
select(-full_name)
df_sample_anon#> # A tibble: 50 × 6
#> ID job x1 x2 x3 x4
#> <int> <chr> <int> <int> <int> <int>
#> 1 31 Transport planner 9 10 6 4
#> 2 13 Medical secretary 8 6 3 5
#> 3 6 Naval architect 8 7 6 3
#> 4 47 Editorial assistant 8 9 4 5
#> 5 27 Arboriculturist 9 9 5 1
#> 6 30 Designer, multimedia 9 9 3 4
#> 7 32 Education administrator 8 9 5 3
#> 8 24 Food technologist 7 10 4 3
#> 9 1 Education officer, museum 8 8 6 4
#> 10 46 Teacher, English as a foreign language 10 8 4 2
#> # ℹ 40 more rowsColumn/Variable Operations
After you import, you often need to separate or combine variables/columns.
This section of R4DS covers the separating functions. There are also unite() functions for the inverse.