Let’s go back to last class’s notes and resolve some outstanding challenges!
tidytext
Today we’ll start with the basics of what “tidy text” is, how to calculate and visualize tf-idf, and a bit about bigrams. We’ll continue next time with more about sentiment analysis.
What is tidy text?
There are many ways to analyze text, but here we are focusing on tidy text. Like tidy data are data with one observation per row, tidy data are data with one token per row. A token is a linguistic unit that could be a “word” or something bigger or smaller, depending on the context.
tf-idf
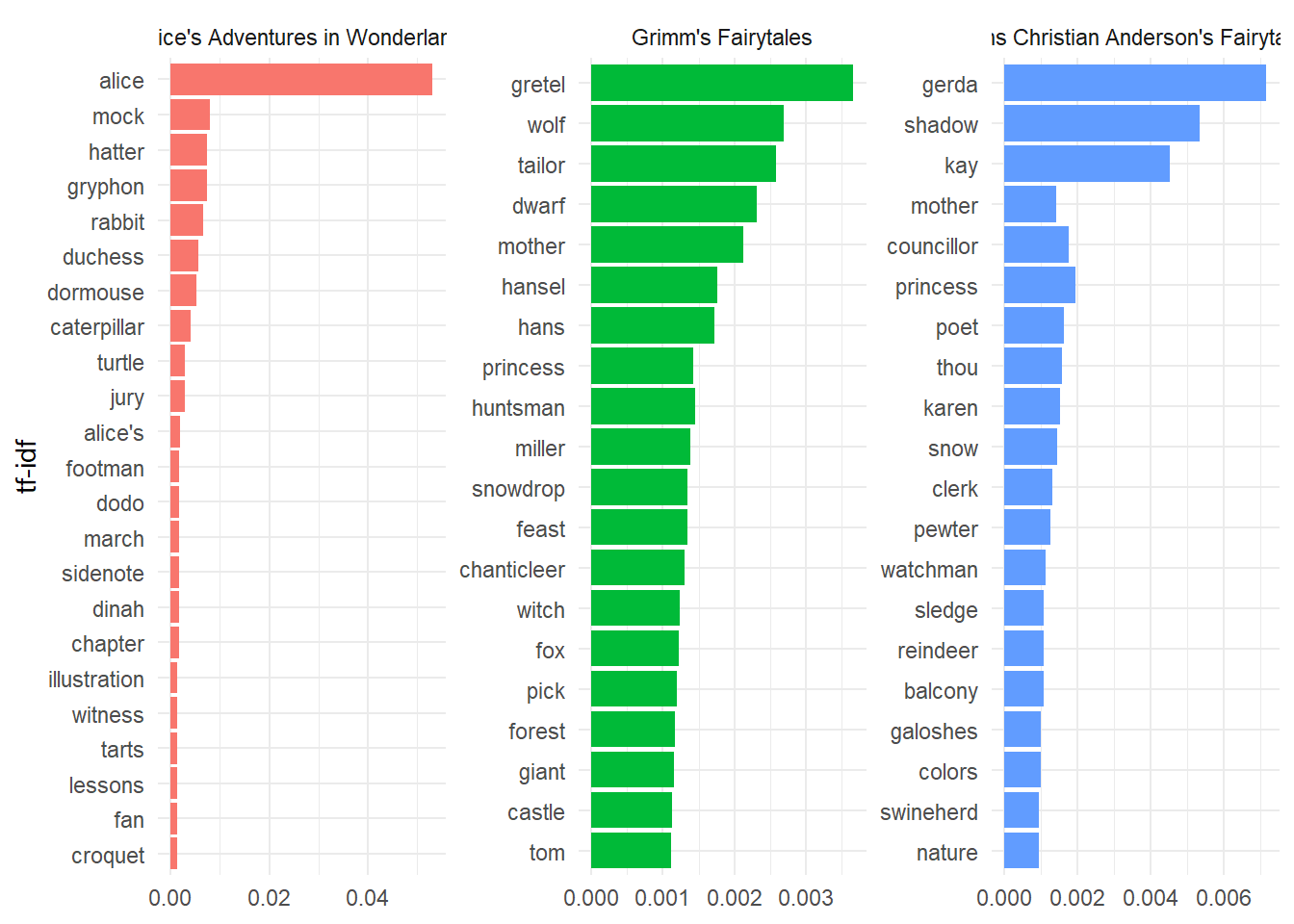
tf-idf stands for term frequency–inverse document frequency, and is intended to measure the “importance” of a term to a document, by comparing frequency across documents. If a word has a high tf-idf for a document, it is more specifically characteristic for that document. These are words that are very common in the specific document, but NOT as high frequency across all documents.
n-grams
n-grams are consecutive sequences of tokens, which can be counted in different “n” sizes - unigrams would be single token frequency, bigrams for sequences of two tokens, trigrams for three, etc.
fairytales_freq <- fairytales_tidy %>%group_by(gutenberg_id) %>%#including this ensures that the counts are by book and the id column is retainedcount(word, sort=TRUE)fairytales_idf <- fairytales_freq %>%bind_tf_idf(word, gutenberg_id, n)fairytales_idf %>%group_by(gutenberg_id) %>%arrange(desc(tf_idf)) %>%top_n(20, tf_idf) %>%ggplot(aes(x = tf_idf, y =reorder(word, tf_idf), fill = gutenberg_id)) +geom_col(show.legend =FALSE) +labs(x =NULL, y ="tf-idf") +facet_wrap(~gutenberg_id, scales ="free") +theme_minimal()
Poll
How would we “unnest tokens” for languages with different writing systems? What challenges might there be?
Poll
Should stopwords be removed before or after a bigram analysis?
---title: "Class 20"subtitle: "More GitHub Pages and Tidy Text"date: 2024-11-05date-format: "YYYY-MM-DD"editor: markdown: wrap: 72editor_options: chunk_output_type: console---```{r}#| echo: FALSE#| include: falselibrary(tidyverse)```## Further ReadingWe're following up on these readings/materials today:- {{< fa external-link >}} [Text Mining with R - Chapter 1](https://www.tidytextmining.com/tidytext.html)- {{< fa external-link >}}[RLadies Freiburg - Tidy Text Analysis: Word frequencies & n-grams](https://www.youtube.com/watch?v=Z6-lBcGOmAo)- {{< fa external-link >}}[RLadies Freiburg - Tidy Text Analysis: Word frequencies & n-grams (github resources)](https://github.com/rladies/meetup-presentations_freiburg/blob/master/2021-06-22_TextAnalysis_ngrams/Tidy%20Text%20Analysis%20-%20Word%20frequencies%20and%20n-grams.Rmd)## AgendaToday we'll focus on:- GitHub pages continued- tidytext basics## GitHub Pages continuedLet's go back to last class's notes and resolve some outstanding challenges!## tidytextToday we'll start with the basics of what "tidy text" *is*, how to calculate and visualize tf-idf, and a bit about bigrams. We'llcontinue next time with more about sentiment analysis.### What is tidy text?There are many ways to analyze text, but here we are focusing on **tidytext**. Like tidy data are data with one observation per row, tidy data are data with *one token per row*. A token is a linguistic unit thatcould be a "word" or something bigger or smaller, depending on the context. ### tf-idf**tf-idf** stands for term frequency–inverse document frequency, and is intended to measure the "importance" of a term to a document, by comparing frequency across documents. If a word has a high tf-idffor a document, it is more specifically characteristic for that document.These are words that are very common in the specific document, but NOT as high frequency across all documents. ### n-grams**n-grams** are consecutive sequences of tokens, which can be counted in different "n" sizes - *unigrams* would be single token frequency, *bigrams* for sequences of two tokens, trigrams for three, etc.### Example from tutorial```{r}library(tidyverse)library(gutenbergr)library(tidytext)fairytales_raw <-gutenberg_download(c(28885, 2591, 1597), mirror ="http://mirrors.xmission.com/gutenberg/")fairytales_raw <- fairytales_raw %>%mutate(gutenberg_id =recode(gutenberg_id,"28885"="Alice's Adventures in Wonderland","2591"="Grimm's Fairytales","1597"="Hans Christian Anderson's Fairytales"),gutenberg_id =as.factor(gutenberg_id))fairytales_tidy <- fairytales_raw %>%unnest_tokens(word, text) %>%mutate(word =str_extract(word, "[a-z']+")) %>%anti_join(stop_words) fairytales_freq <- fairytales_tidy %>%group_by(gutenberg_id) %>%#including this ensures that the counts are by book and the id column is retainedcount(word, sort=TRUE)fairytales_idf <- fairytales_freq %>%bind_tf_idf(word, gutenberg_id, n)fairytales_idf %>%group_by(gutenberg_id) %>%arrange(desc(tf_idf)) %>%top_n(20, tf_idf) %>%ggplot(aes(x = tf_idf, y =reorder(word, tf_idf), fill = gutenberg_id)) +geom_col(show.legend =FALSE) +labs(x =NULL, y ="tf-idf") +facet_wrap(~gutenberg_id, scales ="free") +theme_minimal()```::: {.callout-note .question}#### PollHow would we "unnest tokens" for languages with different writing systems?What challenges might there be?:::::: {.callout-note .question}#### PollShould stopwords be removed before or after a bigram analysis?a. beforeb. after:::### Demo: Chinese TokenizationFrom <https://smltar.com/tokenization.html#tokenization-for-non-latin-alphabets>```{r}library(jiebaR)words <-c("下面是不分行输出的结果", "下面是不输出的结果")engine1 <-worker(bylines =TRUE)segment(words, engine1)```