Class 21
Sentiment Analysis and Lyrics
Preparation Reading
We’re working with these readings/materials today:
Agenda
Today we’ll focus on:
- continuation from last time
- tidytext sentiment analysis
Using APIs with R (Optional)
What is an API, and how do you access one in R? You could start with this guide:
For Homework 3, you can optionally use the {geniusr} package to get lyrics. Note that APIs can be finicky, but let’s try it out!
Awkward installation notes - there is a bug in the main package code, so you need to install a “forked” version from GitHub. You can do so as follows (remove/skip comment character from installation lines):
The documentation for {geniusr} explains how to create and use an access token.
Authenticate
NOTE: you shouldn’t generally put any passwords or access tokens into your documents directly! There are some ways of managing this so you can use them non-interactively, but we don’t have time to cover that now. Once you use the genius_token() function interactively in your project, you should be able to render the document without re-entering it on the same computer. I have set the chunk above to output: false so that it doesn’t show the key in the html output either.
You can get lyrics for one song for a specific artist like this:
hs_adoreyou <- get_lyrics_search(artist_name = "Harry Styles", song_title = "Adore You")
head(hs_adoreyou)#> # A tibble: 6 × 5
#> line section_name section_artist song_name artist_name
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Walk in your rainbow paradi… Verse 1 Harry Styles Adore You <NA>
#> 2 Strawberry lipstick state o… Verse 1 Harry Styles Adore You <NA>
#> 3 I get so lost inside your e… Verse 1 Harry Styles Adore You <NA>
#> 4 Would you believe it? Verse 1 Harry Styles Adore You <NA>
#> 5 You don't have to say you l… Pre-Chorus Harry Styles Adore You <NA>
#> 6 You don't have to say nothi… Pre-Chorus Harry Styles Adore You <NA>To combine multiple dataframes with matching columns/variables, you can use bind_rows():
Sentiment Analysis
Getting sentiments for words:
#> # A tibble: 6,786 × 2
#> word sentiment
#> <chr> <chr>
#> 1 2-faces negative
#> 2 abnormal negative
#> 3 abolish negative
#> 4 abominable negative
#> 5 abominably negative
#> 6 abominate negative
#> 7 abomination negative
#> 8 abort negative
#> 9 aborted negative
#> 10 aborts negative
#> # ℹ 6,776 more rowsJoining and keeping only words that have a sentiment:
#> Joining with `by = join_by(word)`#> # A tibble: 22 × 6
#> section_name section_artist song_name artist_name word sentiment
#> <chr> <chr> <chr> <chr> <chr> <chr>
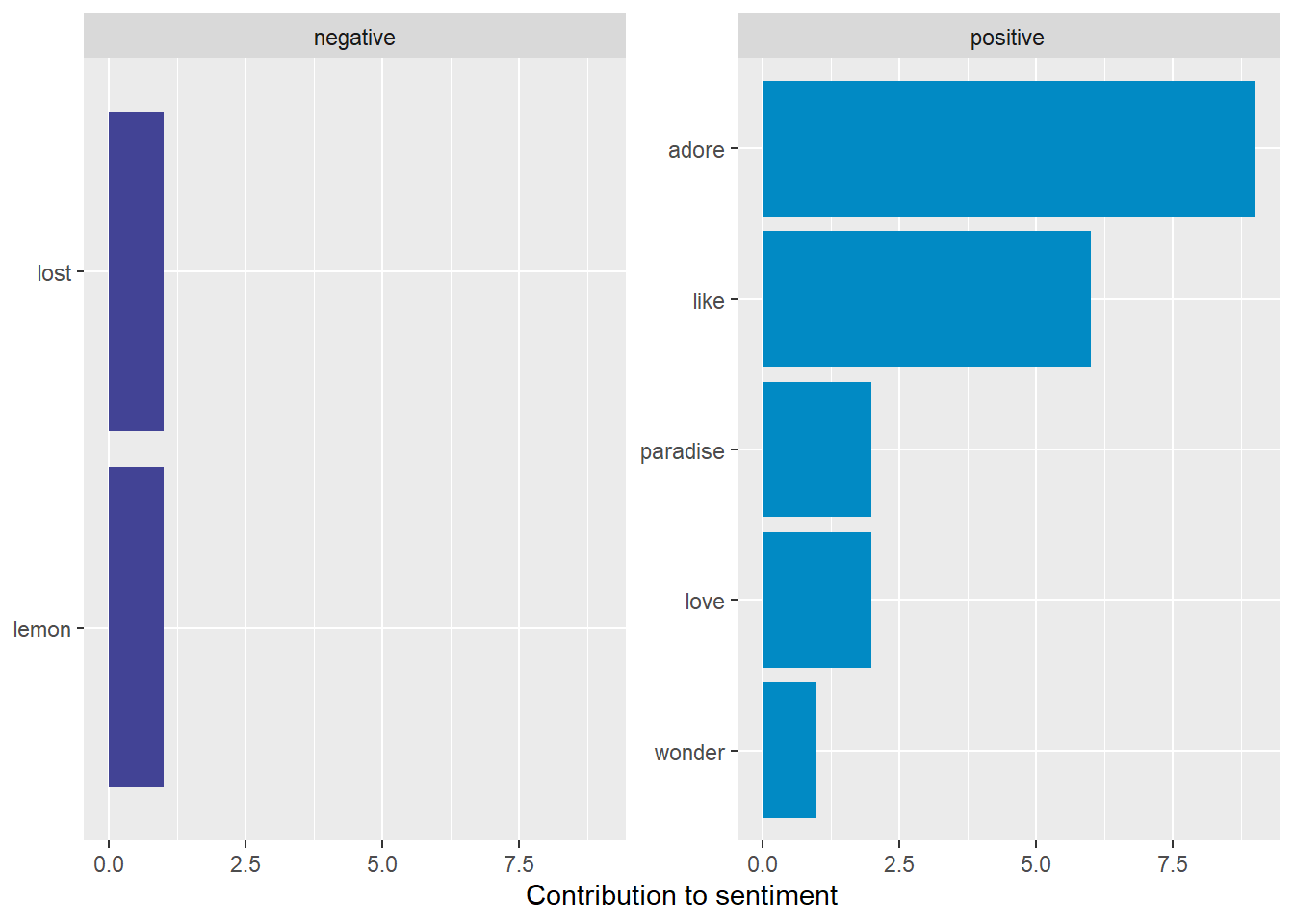
#> 1 Verse 1 Harry Styles Adore You <NA> paradise positive
#> 2 Verse 1 Harry Styles Adore You <NA> paradise positive
#> 3 Verse 1 Harry Styles Adore You <NA> lost negative
#> 4 Pre-Chorus Harry Styles Adore You <NA> love positive
#> 5 Chorus Harry Styles Adore You <NA> adore positive
#> 6 Chorus Harry Styles Adore You <NA> adore positive
#> 7 Chorus Harry Styles Adore You <NA> like positive
#> 8 Chorus Harry Styles Adore You <NA> like positive
#> 9 Verse 2 Harry Styles Adore You <NA> wonder positive
#> 10 Verse 2 Harry Styles Adore You <NA> lemon negative
#> # ℹ 12 more rowsNOTE: most stopwords don’t have sentiments anyway.
#> # A tibble: 2 × 2
#> sentiment n
#> <chr> <int>
#> 1 negative 2
#> 2 positive 20#> Joining with `by = join_by(word)`#> # A tibble: 2 × 2
#> sentiment n
#> <chr> <int>
#> 1 negative 9
#> 2 positive 10Getting More Lyrics
Some other {geniusr} functions that work - some don’t seem to work with the current version of the API, even with the modified package.
#> # A tibble: 1 × 3
#> artist_id artist_name artist_url
#> <int> <chr> <chr>
#> 1 1177 Taylor Swift https://genius.com/artists/Taylor-swift#> # A tibble: 20 × 5
#> song_id song_name song_lyrics_url artist_id artist_name
#> <int> <chr> <chr> <int> <chr>
#> 1 7076626 All Too Well (10 Minute Versi… https://genius… 1177 Taylor Swi…
#> 2 7394358 All Too Well (10 Minute Versi… https://genius… 1177 Taylor Swi…
#> 3 10024009 Fortnight (Ft. Post Malone) https://genius… 1177 Taylor Swi…
#> 4 5793984 cardigan https://genius… 1177 Taylor Swi…
#> 5 5793983 exile (Ft. Bon Iver) https://genius… 1177 Taylor Swi…
#> 6 4508914 Lover https://genius… 1177 Taylor Swi…
#> 7 10024526 loml https://genius… 1177 Taylor Swi…
#> 8 10024578 The Tortured Poets Department https://genius… 1177 Taylor Swi…
#> 9 5794073 the 1 https://genius… 1177 Taylor Swi…
#> 10 10296677 thanK you aIMee https://genius… 1177 Taylor Swi…
#> 11 10024535 Down Bad https://genius… 1177 Taylor Swi…
#> 12 10024520 But Daddy I Love Him https://genius… 1177 Taylor Swi…
#> 13 9538404 Is It Over Now? (Taylor's Ver… https://genius… 1177 Taylor Swi…
#> 14 5793977 august https://genius… 1177 Taylor Swi…
#> 15 6260164 tolerate it https://genius… 1177 Taylor Swi…
#> 16 10024512 I Can Do It With a Broken Hea… https://genius… 1177 Taylor Swi…
#> 17 3210592 Look What You Made Me Do https://genius… 1177 Taylor Swi…
#> 18 6260160 champagne problems https://genius… 1177 Taylor Swi…
#> 19 10024519 The Smallest Man Who Ever Liv… https://genius… 1177 Taylor Swi…
#> 20 5793962 betty https://genius… 1177 Taylor Swi…You can also use lyrics text that you’ve obtained in other ways to read in. Let’s say that I copy the lyrics for a song from the Genius website. I could read them in as an object by creating separating the lines using read_lines():
apple <- read_lines("[Verse 1]
I guess the apple don't fall far from the tree
'Cause I've been looking at you so long
Now I only see me
I wanna throw the apple into the sky
Feels like you never understand me
So I just wanna drive
To the airport, the airport
The airport, the airport
[Verse 2]
I guess the apple could turn yellow or green
I know there's lots of different nuances
To you and to me
I wanna grow the apple, keep all the seeds
But I can't help but get so angry
You don't listen, I leave
To the airport, the airport
The airport, the airport
The airport, the airport
The airport, the airport
[Interlude]
(Yeah, yeah)
I'm gonna drive, gonna drive all night
I'm gonna drive, gonna drive all night
[Verse 3]
I think the apple's rotten right to the core
From all the things passed down
From all the apples coming before
I split the apple down symmetrical lines
And what I find is kinda scary
Makes me just wanna drive
(Drive, drive, drive, dr-dr-dr-drive, drive, drive)
(I'm gonna drive, gonna drive all night)
(I'm gonna drive, gonna drive all night)
(Drive, drive, drive, dr-dr-dr-drive, drive)
[Outro]
I wanna know where you go
When you're feeling alone
When you're feeling alone, do you?
I wanna know where you go
When you're feeling alone
When you're feeling alone, do you?
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you, do you, do you)
(Do you, do you)")Now it’s a character vector. We can turn it into a dataframe to get to a tidytext format, similar to workflow used for the Emily Dickinson poem at the beginning of the Text Mining in R book:
#> # A tibble: 55 × 2
#> song text
#> <chr> <chr>
#> 1 apple "[Verse 1]"
#> 2 apple "I guess the apple don't fall far from the tree"
#> 3 apple "'Cause I've been looking at you so long"
#> 4 apple "Now I only see me"
#> 5 apple "I wanna throw the apple into the sky"
#> 6 apple "Feels like you never understand me"
#> 7 apple "So I just wanna drive"
#> 8 apple "To the airport, the airport"
#> 9 apple "The airport, the airport"
#> 10 apple ""
#> # ℹ 45 more rowsLet’s remove the lines with brackets, and then unnest:
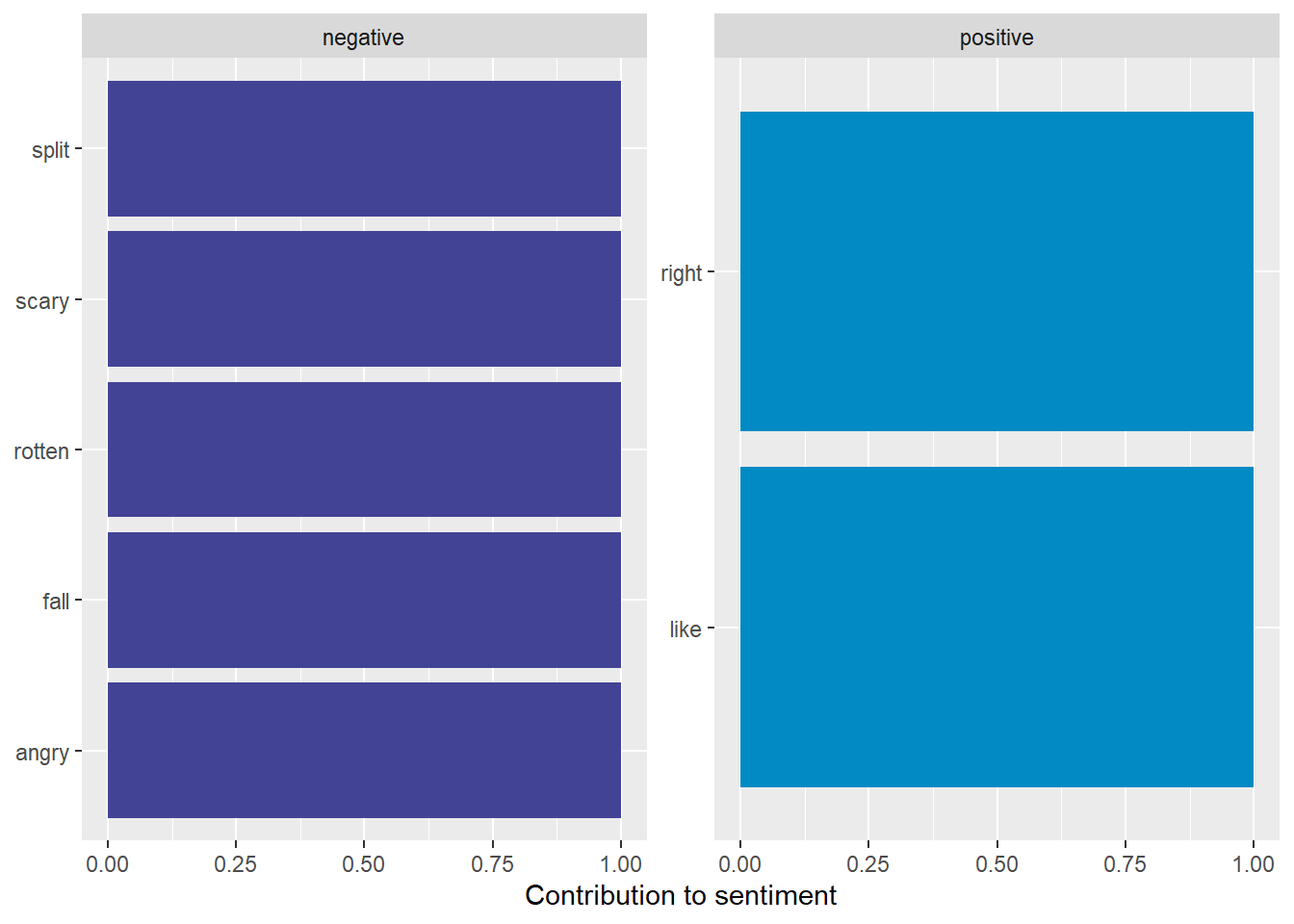
df_apple_words <- df_apple |>
filter(!str_starts(text, "\\[")) |>
unnest_tokens(word, text)
df_apple_words#> # A tibble: 298 × 2
#> song word
#> <chr> <chr>
#> 1 apple i
#> 2 apple guess
#> 3 apple the
#> 4 apple apple
#> 5 apple don't
#> 6 apple fall
#> 7 apple far
#> 8 apple from
#> 9 apple the
#> 10 apple tree
#> # ℹ 288 more rowsPlotting Some Sentiments
Let’s plot some of these:
# install.packages("paletteer")
library(paletteer)
df_mat_sent |>
count(word,sentiment) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(x = n, y = word, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
# using a 'beyonce' palette from the colors
scale_fill_paletteer_d("beyonce::X18") +
labs(x = "Contribution to sentiment",
y = NULL)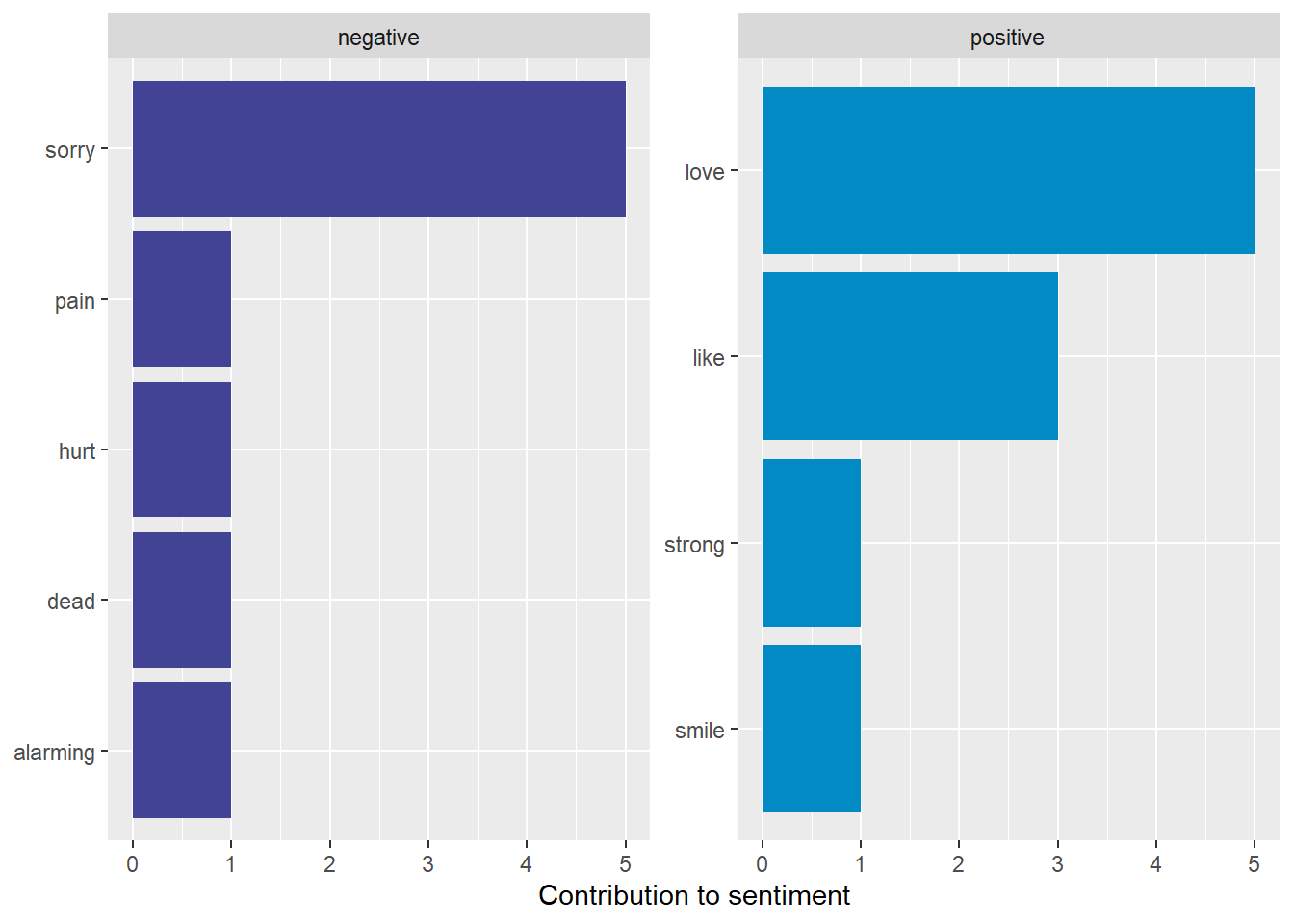
Let’s make this a function:
plot_sentiments <- function(sentiment_data){
sentiment_data |>
count(word,sentiment) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(x = n, y = word, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
# using a 'beyonce' palette from the colors
scale_fill_paletteer_d("beyonce::X18") +
labs(x = "Contribution to sentiment",
y = NULL)
}